
A brief look at network thinking in Complexity: A Guided Tour by Melanie Mitchell
Skip ahead
- Networks abound
- Small-world networks
- Worm brains and Hollywood cliques
- Scale-free networks
- Preferential attachment
- Connective emergence
- Deletion, resilience, and failure
- Network thinking
Networks abound
In every domain and at every scale, we find networks of all sorts. Human economies, ant colonies, and beehives, for instance, are panoplies of busy workers. The animal brain, likewise, is a webwork of neurons and synapses. The World Wide Web too is a sea of webpages and hyperlinks. And even languages are symbolic networks of communicative structures and relations.
Abstract away from these seemingly disparate fields, however, and you’ll find nodes and links that bring these systems into being. Might there exists principles to describe and understand the nature of these networks in more general terms?
In Complexity: A Guided Tour, Melanie Mitchell says the answer is yes. In particular, “high-clustering, skewed degree distributions, and hub structure are characteristic of the vast majority of all the natural, social, and technological networks”.1
To Mitchell, “the presence of these structures is clearly no accident”. To see why, we must first look at two common network models: (1) small-world networks and (2) scale-free networks. So let us take each in turn.
1 Hubs are nodes with many links, much like a popular website on the World Wide Web. Clusters are groups of nodes with greater linkages, much like the clusters between families, neighbors, suburbs, and entire regions. Degree distribution refers to the distribution of nodes with many links (high degree nodes) and very few links (low degree nodes). Skewed distributions suggest then that the ratio between low-degree nodes and high-degree nodes are uneven. In social networks, for example, most people will have a small cluster of friends, while a popular few will have many connections.
Small-world networks
For a start, average path length — or the average number of links between any two nodes using the shortest possible route — can tell us a lot about a network. Just compare, for example, the manner in which information travels in an agile startup versus that of the lumbering, bureaucratic enterprise. Paths and path lengths matter.
In Collective Dynamics of Small-World Networks, Duncan Watts and Steven Strogatz find that random ‘rewiring’ of some links in a ‘regular’ or ordered network can reduce its average path length (Figure 1). They refer to networks with this property as ‘small-world’ (the name was inspired by the six-degrees of separation that characterizes our ‘small-world’ social networks).
Figure 1. Example of a regular and small-world network
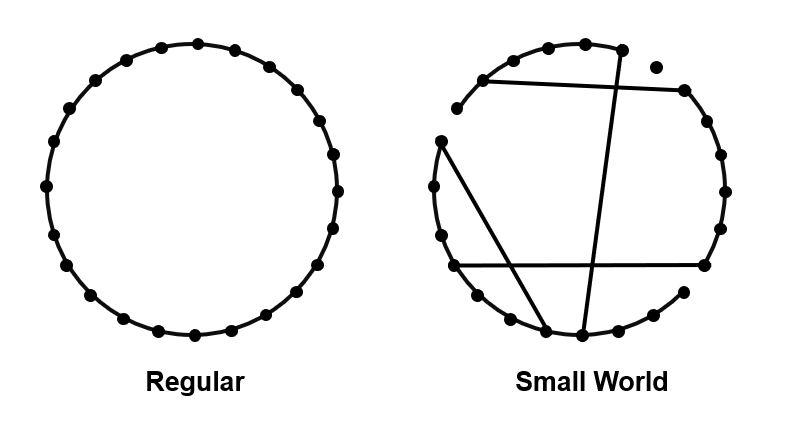
I’ll leave out their numerical examples and network modeling for brevity. But you can imagine, for instance, using the diagram above, how the transition from a regular networks to small-world networks might open new shortcuts, reduce average path lengths, and confer new benefits to the system.
As Watts and Strogatz explain:
“Ordinarily, the connection topology is assumed to be either completely regular or completely random. But many biological, technological and social networks lie somewhere between these two extremes. … Models of dynamical systems with small-world coupling display enhanced signal-propagation speed, computational power, and synchronizability.”
Duncan Watts and Steven Strogatz. (1998). Collective Dynamics of Small-World Networks.
Worm brains and Hollywood cliques
Indeed, many networks in life — from worm brains to Hollywood cliques and electrical grids — are “small-world networks, with low average path lengths and high clustering”, writes Mitchell.
Why might evolutionary processes in nature, society, and technology favor such structures? For one, swift transportation of information and resources is valuable. Think about the supply chains during a great war or the circulatory network of an elite athlete. Short, efficient routes from one node to another can make a competitive difference.
While short path lengths are desirable, network designs are not cost free. Building, maintaining, and repairing dependable long-range linkages is difficult and expensive. Just imagine the chaos if every employee in big business had a direct line to the chief executive!
Small-world networks, by contrast, may balance the trade-offs between shortcuts and cost by using an intermediate number of long-range links to join otherwise disparate clusters together. I liken this to the distribution of highways and suburban roads that characterize our traffic networks.
Searching the Web
Let’s turn to another familiar example: how do we find information on the World Wide Web, which is itself a vast network of web pages and links? We use search engines, of course. But how do the search engines do it?
In short, Google Search uses an algorithm called PageRank, which serves relevant web pages in order of authority. Authority in turn is based on a function of the number, quality, and relevance of other web pages that link to the pages in question.1
Page ranking works because there is a skewed degree distribution of web pages. That is, there are many low-degree pages (pages with few inbound links), and few high-degree pages (pages or hubs with many inbound links).
1Search engine algorithms are obviously more sophisticated than I’ve let on. For those wanting an in-depth explanation, you can see Cornell’s lecture on the PageRank algorithm and Google’s commentary on how search works.
Scale-free networks
The World Wide Web is also a good example of a scale-free network — our second model of interest. Such networks, Mitchell says, have three characteristics. Firstly, they possess a “small-world structure” and “a relatively small number of very high-degree nodes (hubs)”. Secondly, the network contains a lot of variation (or heterogeneity) in the degree of its nodes.
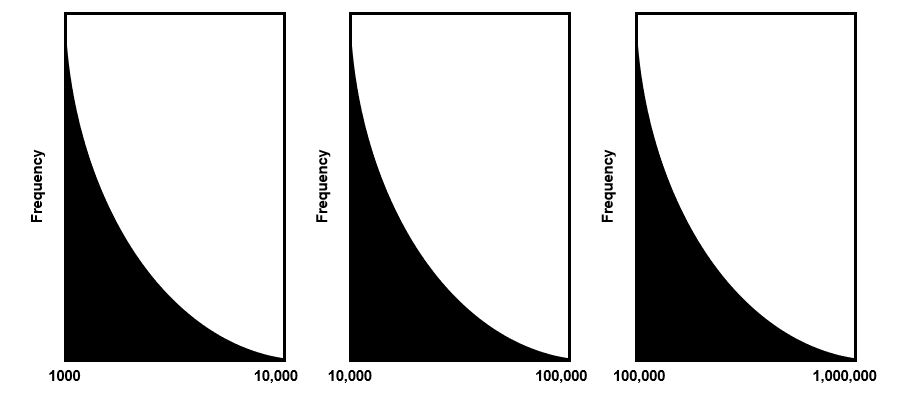
Thirdly and most distinctively, it exhibits the property of “self-similarity”. That is, its degree distribution maintains “the same shape at any scale you plot it” (Figure 2). Indeed, if you draw a histogram of the frequency of web pages by degree (number of inbound links), you would get a power-law distribution across multiple levels of scale (similar to Figure 2).
Figure 2. Example of scale-free and self-similarity
Preferential attachment
Networks, of course, are not static fixtures in time. Nodes and links are added to and removed from networks. Indeed, many networks, from the economy to the Web, are growing and adapting as we speak. Is there anything we can say about the shape and growth of these networks?
In the Emergence of Scaling in Random Networks, Albert Laszlo Barabasi and Reka Albert attribute the growth patterns of scale-free networks to “preferential attachment”. You can imagine, for example, that as new pages are added to the Web, they are more likely to link to popular hubs than to unnoticed pages. This in turn reinforces the distributions already observed.
Mitchell points similarly to the networks of academic citations and best-selling books. While we’d expect citation or sales volumes to be a reasonable signal of quality, popular texts are by nature more likely to be discovered, read, and talked about. Like search on the web, preferential attachment can entrench social structures in a positive feedback loop.
“Most real networks exhibit preferential connectivity. For example, a new actor is most likely to be cast in a supporting role with more established and better-known actors. Consequently, the probability that a new actor will be cast with an established one is much higher than that the new actor will be cast with other less-known actors…The probability with which a new vertex connects to the existing vertices is not uniform; there is a higher probability that it will be linked to a vertex that already has a large number of connections… Growth and preferential attachment are mechanisms common to a number of complex systems, including business networks, social networks…, transportation networks, and so on.”
Albert Laszlo Barabasi and Reka Albert. (1999). Emergence of Scaling in Random Networks
Connective emergence
What’s curious about scale-free networks is the decentralized way in which they come about. There is no mastermind orchestrating the Web. Its nodes, links, and structures emerge organically as more and more people use and make pages; and properties like preferential attachment help networks to keep their shape.
We can find similar cases in other domains too. For example, the interactions and relations between words and grammatical rules give rise to a global symbolic network structure that is our language. Zipf’s law shows in particular that the frequency distribution of word use in the English language follows a scale-invariant power law.
Indeed, some words, like ‘the’ or ‘a’, are used a lot because of their connective role. Other words, like “big” and “short”, are used frequently not just because they are useful, but because they are easy to recall and combine too. Meanwhile, esoteric words, like consanguineous and omphaloskepsis, are rarely used for reasons you can guess.
Deletion, resilience, and failure
Another noteworthy feature of scale-free networks, Mitchell writes, “is their resilience to the deletion of nodes”. A scale-free network of sufficient size can withstand shocks without compromising its heterogeneity, small worldness, and clustering. Random deletions, after all, are more likely to target low-degree nodes than high-degree nodes given its structure.
This in of itself, however, reveals the weakness of scale-free networks. Delete one too many hubs and you risk the network in its entirety. Indeed, the financial system can tolerate the occasional robbery at your local branch or ATM (low-degree). Hacking and compromising the central bank (high-degree), on the other hand, would be catastrophic.
“In short, scale-free networks are resilient when it comes to random deletion of nodes, but highly vulnerable if hubs go down or can be targeted for attack.”
Melanie Mitchell. (2009). Complexity: A Guided Tour.
Many of these properties seem to appear in brain networks too. As Mitchell explains, “we know that individual neurons die all the time, but, happily, the brain continues to function as normal”. Evolution seems to have favored brains with small-world-like resilience (although damage to critical hubs can have devastating effects on the network overall).
Cascades and inevitable hazards
Cascading failures are also possible due to interconnections in a network. Power outages in one part of the electrical grid network, for example, can lead to overload and failure elsewhere. Likewise, a bank run or financial panic in one locale can spread into other regions or asset classes (see also the E. coli effect).
As Mitchell explains:
“Cascading failures provide another example of “tipping points,” in which small events can trigger accelerating feedback, causing a minor problem to balloon into a major disruption. Although many people worry about malicious threats to our world’s networked infrastructure from hackers or “cyber-terrorists,” it may be that cascading failures pose a much greater risk. Such failures are becoming increasingly common and dangerous as our society becomes more dependent on computer networks, …missile defense systems, electronic banking, and the like. As Andreas Antonopoulos… has pointed out, “the threat is complexity itself.”
Melanie Mitchell. (2009). Complexity: A Guided Tour.
In How Complex Systems Fail, Richard Cook writes that complex systems “are inherently and unavoidably hazardous by their own nature”. Our transport, healthcare, financial, and energy networks, for instance, are products of learning and adaptation to a very long history of trial and error, and failure. It follows that the disasters that do emerge in modern systems are usually a product of “multiple failures” interacting in surprising, nonlinear ways that are not easy to spot before the fact.
Network thinking
Indeed, while evolution has had billions of years to fine-tune the networks of nature, humans are only beginning to understand the nature and consequences of their own systems. Can you imagine running a multinational enterprise as smoothly and efficiently as our circulatory system or immune system?
It goes without saying that learning about how networks work and fail is of real interest to us. As Mitchell notes, ongoing research into network science — in areas like self-organized criticality and highly optimized tolerance — may bring new insights and applications in the future.2
More than that, of course, is the need for “network thinking” — to view systems, structures, and relations in a more holistic light. Only then can we begin to make true sense of our complex, interdependent world.
As Mitchell writes:
“Network thinking means focusing on relationships between entities rather than the entities themselves… Scale-free degree distributions, clustering, and the existence of hubs are the common themes… Network thinking is providing novel ways to think about difficult problems such as how to do efficient search on the Web, how to control epidemics, how to manage large organizations, how to preserve ecosystems, … and, more generally, what kind of resilience and vulnerabilities are intrinsic to natural, social, and technological networks, and how to exploit and protect such systems”.
Melanie Mitchell. (2009). Complexity: A Guided Tour.
2 Do not be quick to assume, however, that all complex networks in life exhibit small-world, scale-free, or power-law features. There remains a lot for us to learn about networks. Still, the emerging principles we have so far makes the science of networks most intriguing and promising.
Sources and further reading
- Mitchell, Melanie. (2009). Complexity: A Guided Tour.
- Cook, Richard. (1998). How Complex Systems Fail.
- Watts, Duncan, & Strogatz, Steven. (1998). Collective Dynamics of ‘Small-World’ Networks.
- Barabasi, Albert-Laszlo, & Albert, Reka. (1999). Emergence of Scaling in Random Networks.
Related posts
- What’s Eating the Universe? Paul Davies on Cosmic Eggs and Blundering Atoms
- The Dragons of Eden — Carl Sagan on Limbic Doctrines and Our Bargain with Nature
- The Unexpected Universe — Loren Eiseley on Star Throwers and Incidental Triumphs
- Bridges to Infinity — Michael Guillen on the Boundlessness of Life and Discovery
- Ways of Being — James Bridle on Looking Beyond Human Intelligence
- Predicting the Unpredictable — W J Firth on Chaos and Coexistence
- Order Out of Chaos — Prigogine and Stenger on Our Dialogue With Complexity
- How Brains Think — William Calvin on Intelligence and Darwinian Machines
- The Lives of a Cell — Lewis Thomas on Embedded Nature
- Infinite in All Directions — Freeman Dyson on Maximum Diversity